Host Based Risk Scoring (Part 2): Calculating the Vulnerability Level of a System
06:16:2018
This is Part 2 of the Host Based Risk Scoring series. If you haven’t checked out Part 1, check out the post at Host Based Risk Scoring (Part 1). Please note that information in these articles are taken from my personal ideas and experience. I’d love to hear your comments and thoughts on these concepts. Feel free to leave them at the bottom of the post.
In the last post, we talked about how to calculate true host “Risk” at a conceptual level. In this post, we’re going to dive a little deeper into that concept and put some real numbers to it. At the end of the post, there is a link to a “Risk-o-meter_Spreadsheet” that allows you to play with the inputs and see what the total risk score comes out to be.
Host Level Vulnerability Scoring
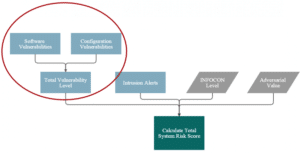 When people normally talk about “Risk”, they focus on the vulnerability level of a system. The vulnerability level is an important part of Risk scoring process. For the first section, we’ll concentrate on how to put calculations to the vulnerability level.
When people normally talk about “Risk”, they focus on the vulnerability level of a system. The vulnerability level is an important part of Risk scoring process. For the first section, we’ll concentrate on how to put calculations to the vulnerability level.
Vulnerability scoring is not a new concept. Organizations such as MITRE, the Forum of Incident Response and Security Teams (FIRST), and the National Institute of Standards and Technology (NIST) have been providing enumerations and vulnerability scoring calculations for years. Back in November 2009, NIST, in conjunction with MITRE and other federal agencies, developed the Security Content Automation Protocol (SCAP). The current revision of SCAP is Version 1.2 (released Sept 2011). Details of the protocol can be found in NIST Special Pub 800-126 (Rev. 2). If you are interested in the details surrounding how vulnerability benchmarks are designed and created, that is a great place to start.
Broadly Categorizing Vulnerabilities
Software Vulnerabilities
Software flaws that allow for remote code execution, privilege escalation, unintended information disclosure, etc. (These are often identified by CVEs or IAVM numbers)
Configuration Vulnerabilities
Configurable items such as password hashing algorithms, User Lockout Thresholds, etc. (Often identified with CCEs or STIG numbers)
The total vulnerability category score is calculated as the sum of the Software Vulnerability Score and the Configuration Vulnerability Score:
Software Vulnerabilities
Software Vulnerabilities come out almost every day, due to the hard work of the vulnerability and pentesting community. When a vulnerability gets reported, it is tracked in the NIST Vulnerability Database (NVD).
For the Software Vulnerability Score, we’ll utilize the Common Vulnerability Scoring System (CVSS), originally developed by FIRST, and the Common Vulnerability Enumeration (CVE), and currently maintained by MITRE. CVSS is a standard score based on numerous Base, Temporal, and Environmental metrics. NIST currently provides a CVSS score and CVE identifier to every vulnerability currently tracked . The total software vulnerability score is implemented as the sum of all of the CVSS values found to be vulnerable on the system.
Configuration Vulnerabilities
Configuration Vulnerabilities are a bit harder to score. There has been a lot of work around the Common Configuration Scoring System (CCSS) that is designed to score configuration vulnerabilities associated with Common Configuration Enumerations (CCE). However, it is still new and not all CCE identifiers have been assigned values. For more information on CCSS, see NIST IR 7502.
For purposes of our calculations, we’ll be concentrating on the DISA Security Technical Implementation Guide (STIG) categories as a means of scoring the vulnerabilities.
STIG Configurations
The STIGs are a valuable resource provided by the Defense Information Systems Agency (DISA) to set the security standards for Department of Defense information systems. Each guide covers a specific technology or application. If you aren’t familiar with them, I would highly suggest checking out the DISA IASE portal for more information on them.
Each STIG configuration item is provided in four categories, depending on their severity:
- CAT I – Vulnerabilities that allow an attacker immediate access into a machine, allow super user access, or bypass a firewall.
- CAT II – Vulnerabilities that provide information that have a high potential of giving access to an intruder.
- CAT III – Vulnerabilities that provide information that potentially could lead to compromise.
- CAT IV – Vulnerabilities that provide information that will lead to the possibility of degraded security.
For configuration scoring purposes, we’ll use a weighted scoring system to calculate the total configuration vulnerability score. The following weights are given to the system:
| Vul Category | Score |
|---|---|
| CAT I | 10 |
| CAT II | 6 |
| CAT III | 3 |
| CAT IV | 1 |
The total configuration score can be calculated with the following formula:
Calculating the Potential of Compromise Score
Determining if a system has been compromised has been the subject of a lot of research and discussion. This blog will only attempt to address a small set of calculations (to help spur the conversation) so as to demonstrate the ability to calculate the overall risk score. As an simplistic example, you could use Host Intrusion Detection Alerts (multiple severities) like SELinux or McAfee HIPS, Unsuccessful Audit Log Alerts, and/or Activity occurring at Abnormal Hours.
Further inputs can be used to enhance the potential of compromise score depending on the software and detection/protection capabilities that you have deployed (e.g. Antivirus alerts, firewall alerts, netflow, anomaly detection, etc.).
One common problem of kernel-based Host Intrusion Detection Systems, such as McAfee HIPS, is that more alerts does not necessarily mean a higher chance of actual intrusion. Installing software or patches can trigger numerous alerts in a short amount of time. The formulas below attempt to take this into account by utilizing both a weighted score and a square root algorithm.
The following equations provide the calculated scores
Threat Score
The term “threat” can have multiple meaning. For the purpose of this blog posting, we’ll define it as “the likelihood that an attack will occur, based on an adversary’s intent, capabilities, and previous actions”. Although this is a blog about calculating risk to individual hosts or devices, the threat is generally the same for an entire system, enclave, or entity. Many entities have overall threat conditions based on intelligence that is gathered. An generic example of this the US Dept of Defense uses is “Force Protection Condition“. The US Strategic Command took a note from this idea and created the concept of Information Condition (or INFOCON) and defined different levels of threat based on Cyber threat intelligence. These levels are conveniently numbered 1-5 based on the likelihood that an attack will occur.
For the purposes of our calculations, we’ll assume that this is a number (1-5) that is calculated based on external intelligence and we’ll simply plug it into the formula. A risk scoring application would need to have the ability to get a way to update the threat number from an external source.
Adversarial Value
One question that is often over-looked in the realm of security is “How valuable is the data or access that I’m protecting?” That question should be one of the driving factors determining how much resources you put into the protection of it.
An entity’s Domain Controller or Certificate Authority is clearly more valuable than a receptionist laptop (or your grandmothers Pentium III desktop).
However, from an individual application or enterprise device perspective, this can be a confusing question. For example, the consumer media systems on an aircraft may not seem like a very valuable target, but as one security researcher has shown, access to non-valuable system such as that, can lead to further access to critical systems.
A whole realm of research can go into this area. For the sake of keeping this posting short, we’ll just call it a static value of 1-10 (and maybe I’ll get back to this concept in a separate article).
Wrapping it all into a Total Risk Score
The concepts behind the formula for calculating the “Total Risk Score” of the system can be found in Host Based Risk Scoring (Part 1). The actual formula I came up with is:

This calculation takes into account the overall scores from all four categories of input. The following screenshot provides an example of a spreadsheet for performing the calculation using all four inputs. You can also download the example Riskometer_Spreadsheet that was created to show how the score increases with certain inputs.
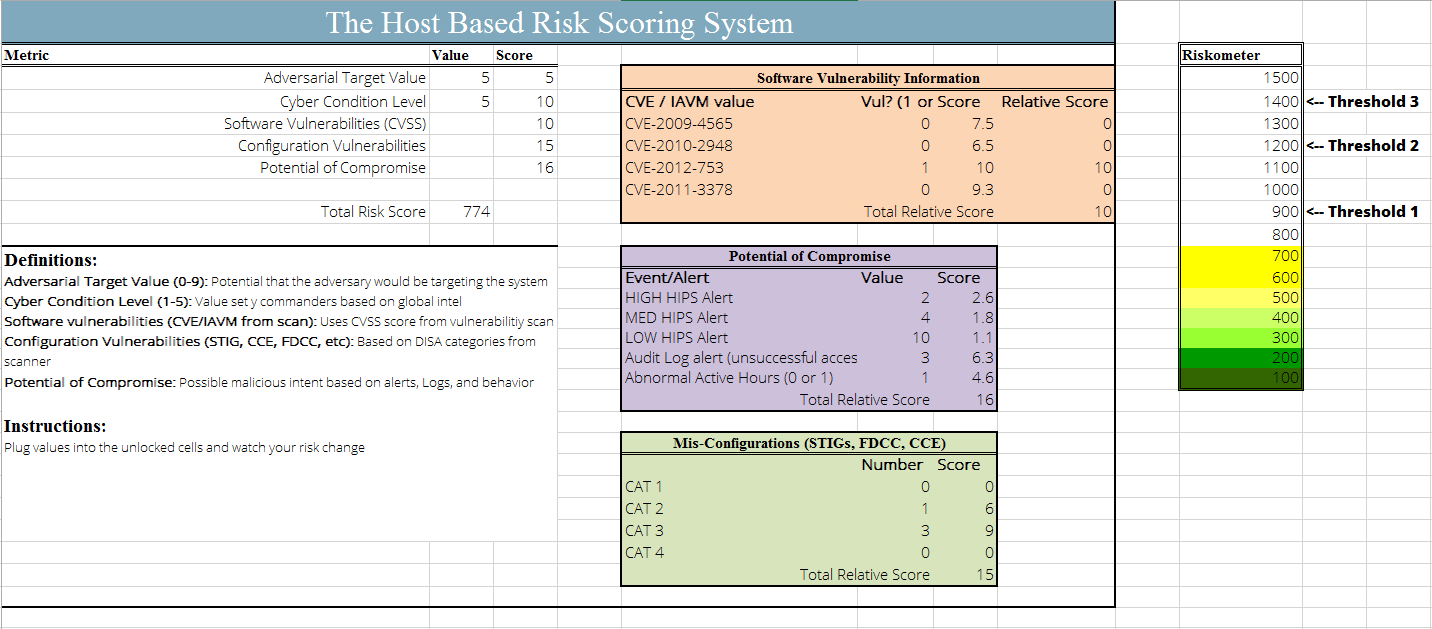
In the example above, the current INFOCON level is 5, the system has a mid-level target value, one critical software vulnerability (CVSS of 10.0), one CAT II configuration vulnerability, and three CAT III configuration vulnerabilities. These problems alone would have only added up to a total score of 180. However, the results of a HIGH Intrusion alert and three unsuccessful audit alerts has increased the score to a level of 930, which should be considered a medium-to-high risk.
To show how the score changes, the following table shows what the total score would have been at different INFOCON levels:
| INFOCON | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|
| Total Score | 774 | 1094 | 1340 | 1548 | 1730 |
Similar to the one above, the following table depicts how the score would change with at different adversarial values:
| Adversarial Value | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Total Score | 282 | 421 | 544 | 660 | 774 | 887 | 1001 | 1116 | 1232 | 1349 |
Thanks for checking out some of my ideas.
Related Articles
Computational Fluid Dynamics within SealingTech Servers
– By Austin McAlexander SealingTech is proud to provide our customers and mission partners with industry leading carry-on compliant server hardware while maintaining the performance characteristics of traditional data center…
The Importance of Compliance in Cybersecurity
More than ever, cybersecurity, as an industry and as a field, has been growing exponentially in terms of the workforce and reach. From commercial and conglomerate entities such as banks,…
DCO: Do You Know What Your Network Security Systems are Looking For?
Over the past 3 years, I have been supporting Defensive Cyber Operations (DCO) capabilities for various Department of Defense (DoD) customers, along with an additional 7 years within Network Security…
Sign Up for Our Newsletter
Get all the recent SealingTech news and updates right to your inbox!
Expect the best cybersecurity ebooks, case studies and guides - all in one place, once a month. Connect with us today!